
Sabemos que é inevitável que diferentes áreas da empresa busquem e utilizem mais de uma solução de software, com frequência desenvolvidas por mais de um fornecedor. Entretanto, para evitar desperdícios e erros, é fundamental que essas soluções funcionem de maneira integrada.
Em nossas consultorias, ajudamos profissionais da área de tecnologia a integrar aplicações utilizando arquiteturas consistentes e ferramentas consagradas, como o Apache NiFi.
Neste post, apresentamos o NiFi, compartilhando alguns de seus conceitos fundamentais, além de algumas ideias extraídas de um breve exemplo de extração de dados da Wikipedia.
NOTA DO ELEMAR: A autoria desse post é do Tiago Tartari. Eu sou editor.
O que é o Apache NiFi?
O NiFi é um software para automatizar o fluxo de dados entre sistemas de software. Ele foi criado e é mantido pela Apache Foundation.
Ele se destaca por ser:
- Confiável e muito poderoso;
- Totalmente independente. Ou seja, sem dependências para outros softwares instalados para funcionar;
- Fácil de usar, com interface de usuário rodando no browser;
- Altamente configurável e expansível;
- Escalável;
- Extremamente seguro.
Em nossa experiência, utilizamos o Apache NiFi para promover integração entre aplicações sem precisar escrever código específico para isso.
Obtendo e executando o Apache NiFi
O Apache NiFi é open-source e está disponível para download na página oficial do projeto. Ele também possui uma imagem docker.
docker run --name nifi -p 8080:8080 -d apache/nifi
Abaixo, temos um preview da tela que você deverá ver ao acessar o endereço onde o NiFi está configurado para trabalhar.
O NiFi está pronto para funcionar. E agora?
O primeiro passo para configurar uma integração usando o Apache NiFi é configurar, na ferramenta, um novo Process Group.
De forma simplificada, o Process Group é onde configuramos um fluxo de dados onde será operacionalizada a integração.
Para criar um Process Group, precisamos apenas especificar um nome.
O nome que iremos escolher não é particularmente relevante. Nesse exemplo, optei por utilizar “wikipedia”, por exemplo.
Podemos especificar quantos Process Group considerarmos necessários.
Definindo o gatilho para o processo de integração
Os fluxos de dados definidos no NiFi são sempre iniciados em resposta a ocorrência de um determinado estímulo (gatilho).
O NiFi já possui em sua instalação padrão um conjunto amplo de Processors (unidades de processamento do NiFi) capazes de “escutar” diferentes tipos de estímulos do ambiente.
Neste post, vamos preparar o NiFi para escutar a ocorrência de uma mensagem em uma fila do RabbitMQ.
docker run -d --hostname rabbit --name rabbit -p 15672:15672 -p 5672:5672 -p 25676:25676 rabbitmq:3-management
O processo de configuração é extremamente intuitivo. Editando o Process Group, basta adicionarmos um Processor para consumir de uma fila AMQP (que é o protocolo implementado pelo RabbitMQ).
Cada processor, no NiFi, é identificado com um ID e um nome.
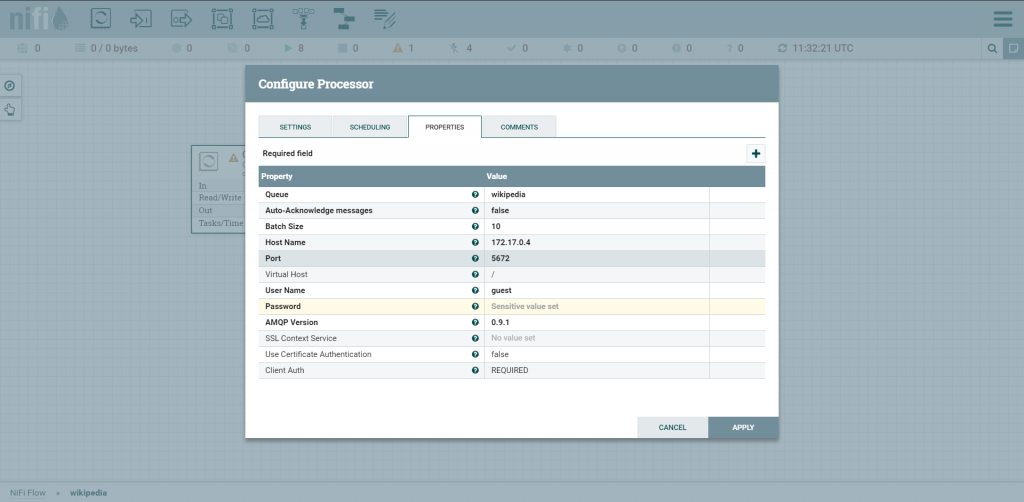
Antes de avançarmos, como você já deve esperar, precisamos configurar o sistema para acessar nosso servidor Rabbit. Na aba Properties ajustamos a configuração da fila, hostname, virtual host, user name e password.
Podemos adicionar diversos processors em nosso Process Group, sensíveis a diversos gatilhos. Ou seja, podemos ter diversos pontos de partida para a integração.
Utilizando dados dos Gatilhos na Execução do Fluxo
No nosso exemplo, o gatilho que iremos receber do RabbitMQ conterá um JSON com dados que iremos utilizar durante a execução.
A extração de dados de um JSON, no NiFi, é uma atividade genérica executada por um Processor. Podemos conectar diversos Processors especializando o tratamento do nosso fluxo de dados.
NOTA DO ELEMAR: Se chegou até aqui, já entendeu que podemos utilizar o NiFi para, facilmente, ouvir de uma fila e publicar para um Brocker criando modelos interessantes de mensageria. Certo?
De fato, o NiFi é uma tecnologia que facilita, e muito, a implementação inteligente dos Patterns de Integração descritos no excelente “Enterprise Integration Patterns: Designing, Building, and Deploying Messaging Solutions“.
O Processor que iremos adicionar chama-se EvaluateJsonPath.
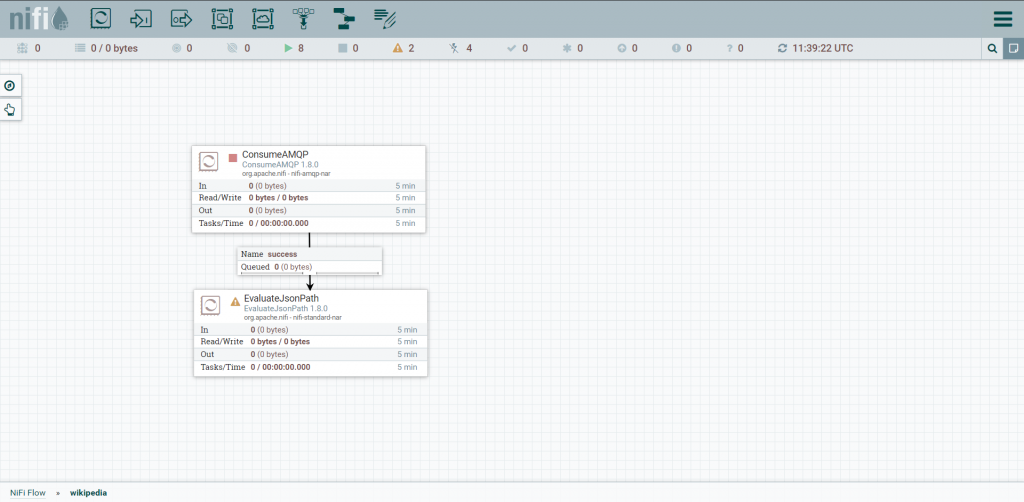
Usaremos este processor para interpretar o JSON e criar um flow-attribute – uma espécie de variável do fluxo que poderemos consultar na execução de outros processors.
NOTA DO ELEMAR: O que temos aqui é a implementação do pattern arquitetural Pipes And Filters.
Tratando erros na execução do fluxo
Assuma que uma mensagem, em formato inválido, seja enviada para a fila do RabbitMQ. O que fazer?
No NiFi, os Processors que podem encontrar problemas em sua execução permitem que definamos processors para caso de sucesso e de falha.

Em cenários de integração, essa feature é extremamente relevante por permitir que tomemos ações corretivas, mesmo que tardias, sem comprometer por tempo prolongado a integridade dos diversos sistemas.
Consumindo serviços de terceiros
Nesse post, queremos pesquisar na Wikipedia por termos que recebemos através de mensagens no RabbitMQ.
O NiFi fornece um processor para fazer requisições HTTP.
Repare que é possível indicar diversas conexões a partir desse processor, incluindo uma lógica de retentativa (que iremos implementar, sem detalhar aqui).
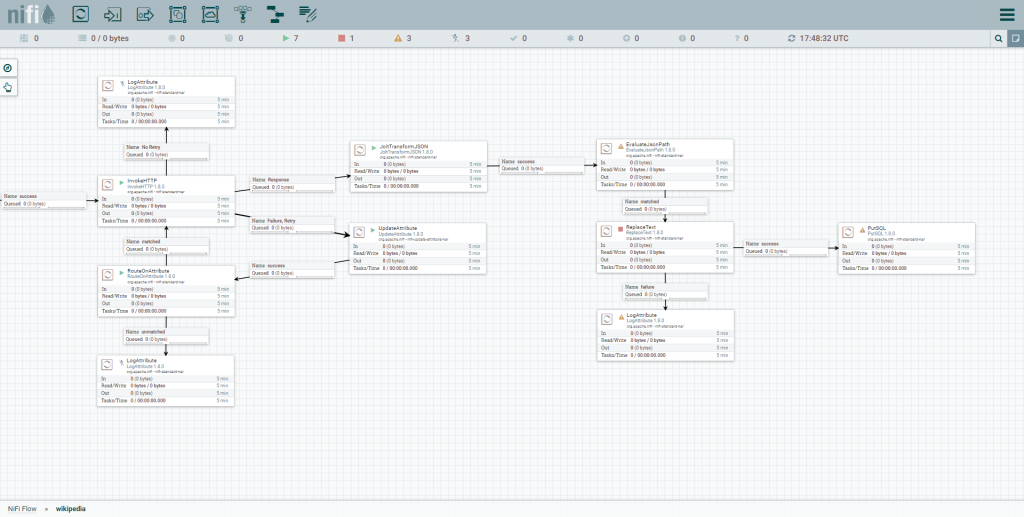
Não se deixe assustar pela aparente complexidade desse fluxo. Na prática, o que fizemos foi construir uma lógica visualmente (sem código).
Não é nosso objetivo falar sobre a API da Wikipedia aqui. Mas, para compreensão, veja um exemplo comum de retorno.
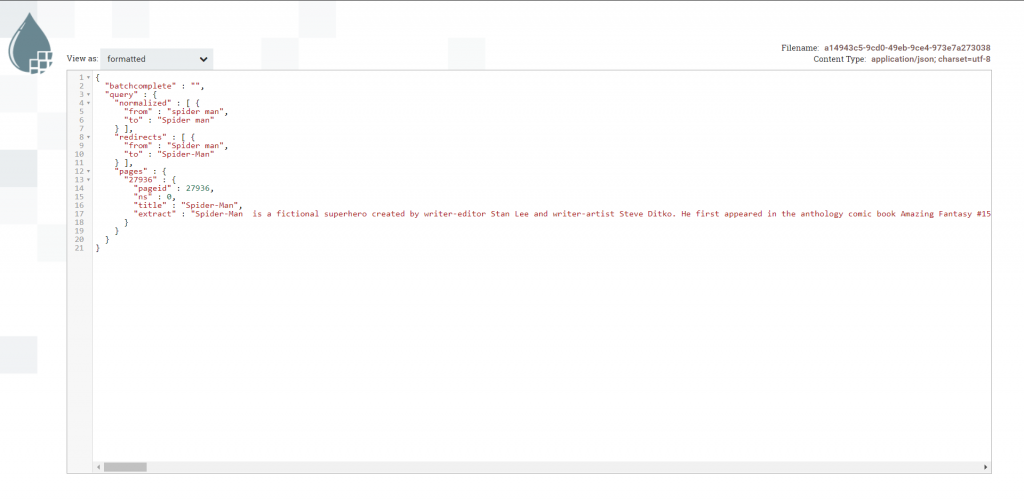
Considerando que recebamos o termo “spider man” na mensagem do Rabbit, este seria o resultado de uma requisição Http para essa pesquisa.
“Traduzindo” mensagens
O NiFi possui recursos nativos para “tradução” de mensagens. Ou seja, podemos receber uma mensagem em um determinado formato e modificar esse formato para algo mais apropriado.
NOTA DO ELEMAR: Mais uma vez, temos a implementação de um pattern de integração consagrado – Message Translator
No nosso exemplo, gostaríamos de mudar o “formato” do JSON que recebemos da Wikipedia por outro mais amistoso.
NiFi oferce um Processor extremamente útil, chamado JoltTransformProcessor, que permite que mudemos o “shape” de um Json usando JOLT.
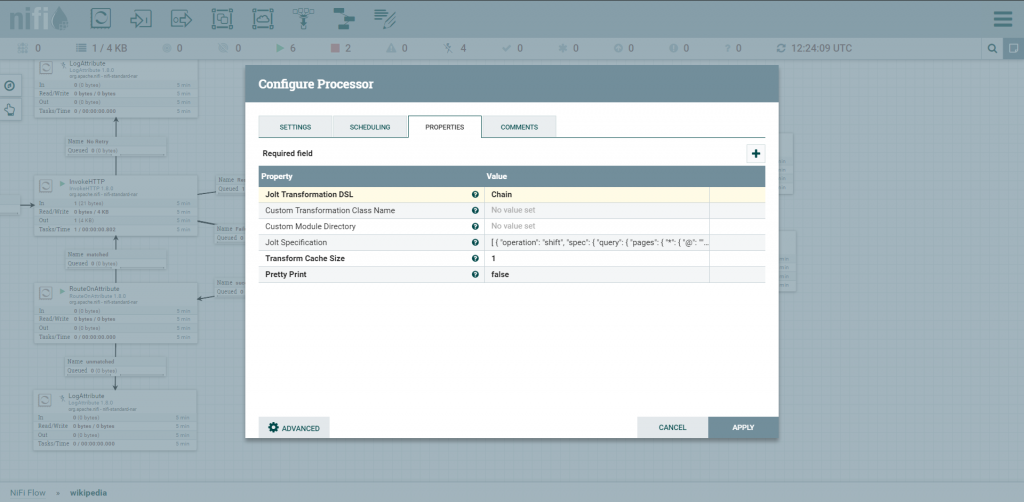
Clicando nas configurações do PROCESSOR JoltTransformJson e clicando em advanced encontraremos um editor para fazermos a transformação do JSON.
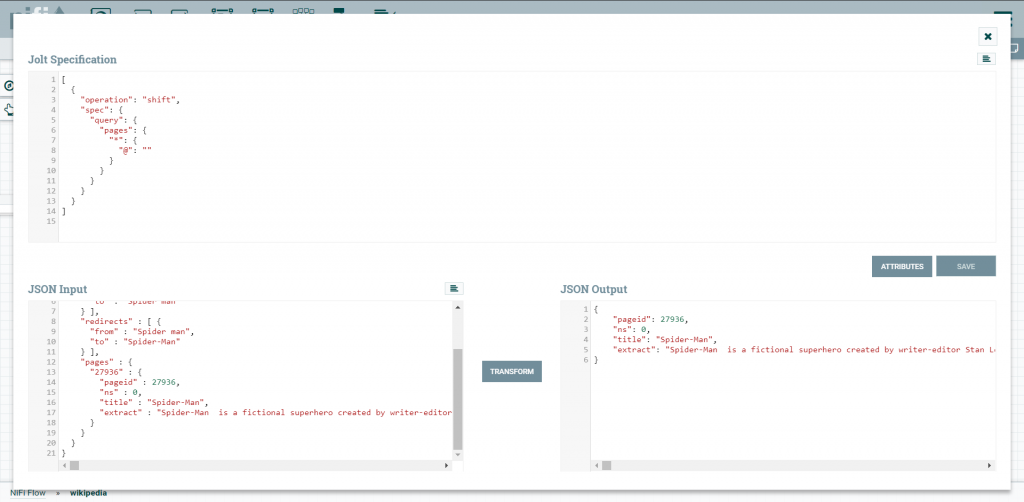
Em JOLT Specification criei o modelo de como meu JSON irá ficar, em JSON Input coloquei o retorno que esperava da API e … pronto! Temos uma tradução de JSON.
Traduzindo mensagens em instruções SQL
Usando a mesma lógica, podemos transformar um JSON em SQL. Com um processor ReplaceText montamos uma instrução SQL facilmente para, eventualmente, interfacear com uma base SQL server.
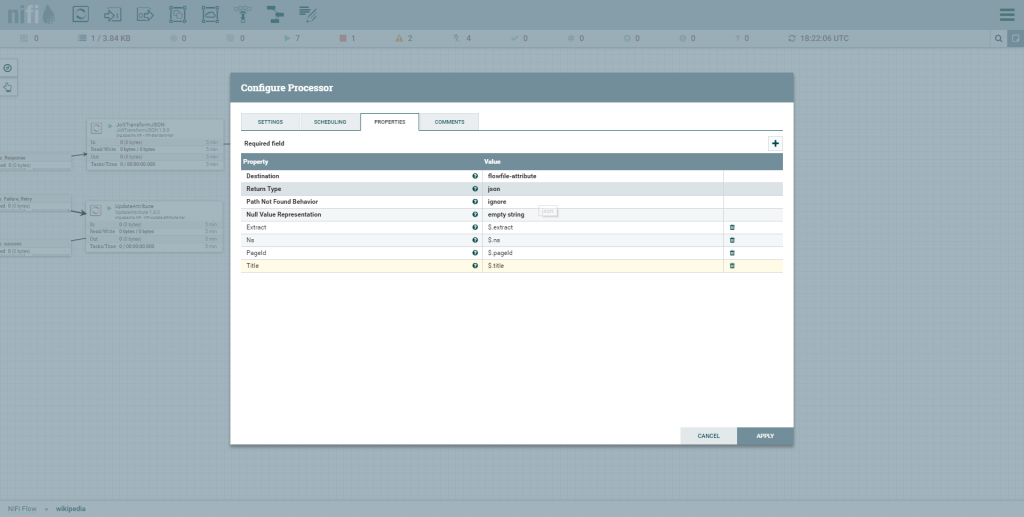
Bem, assim ficou o EvaluateJsonPath.

No ReplaceText montamos toda instrução SQL para salvar em nosso banco de dados. Percebam que utilizei uma função replaceAll para eliminar aspas simples.
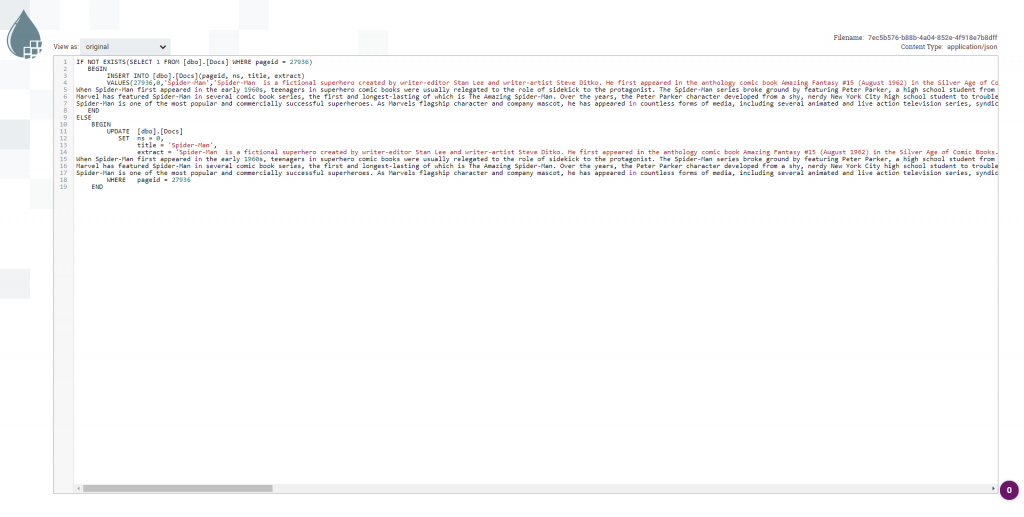
Este foi o resultado final do ReplaceText, a instrução SQL prontinha para ser executada.
Interagindo com um banco de dados relacional
Agora é o momento de configurar o PutSQL – processor que permite que executemos instruções em uma base de dados.
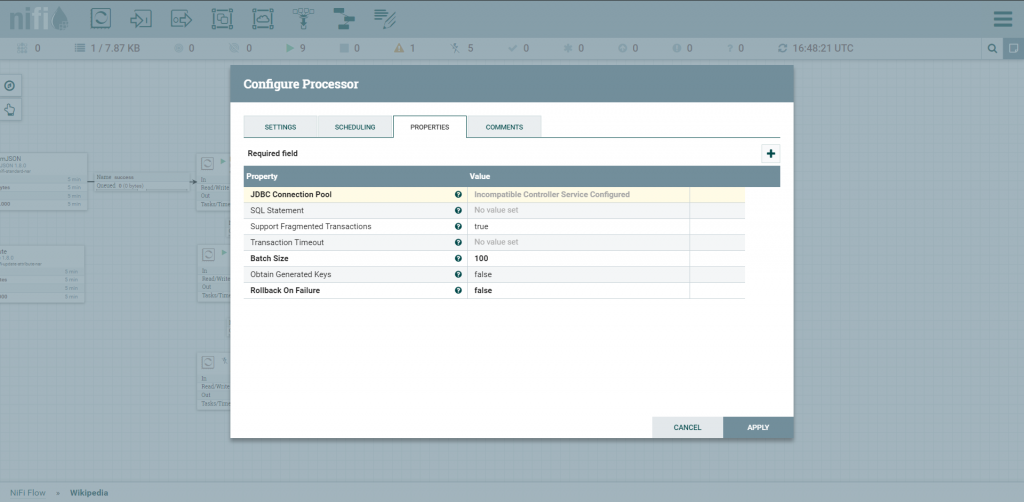
A conexão ocorrerá através de JDBC.
And… Action!
O simples fato de definirmos um processor, configurando-o de forma apropriada, já o autoriza a funcionar.
Cada estímulo em um processor que opere como ponto de partida inicia um dataflow (fluxo de dados). Além disso, cada processor poderá ser pausado facilmente no painel de configuração (repare no play, no canto superior esquerdo no processor).
A possibilidade de poder pausar um processor pode ser extremamente útil em condições de instabilidade.
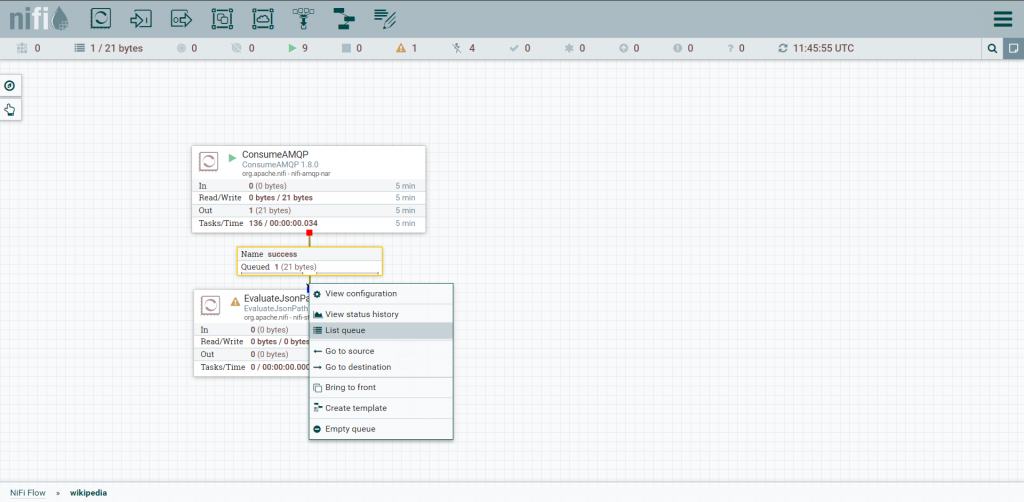
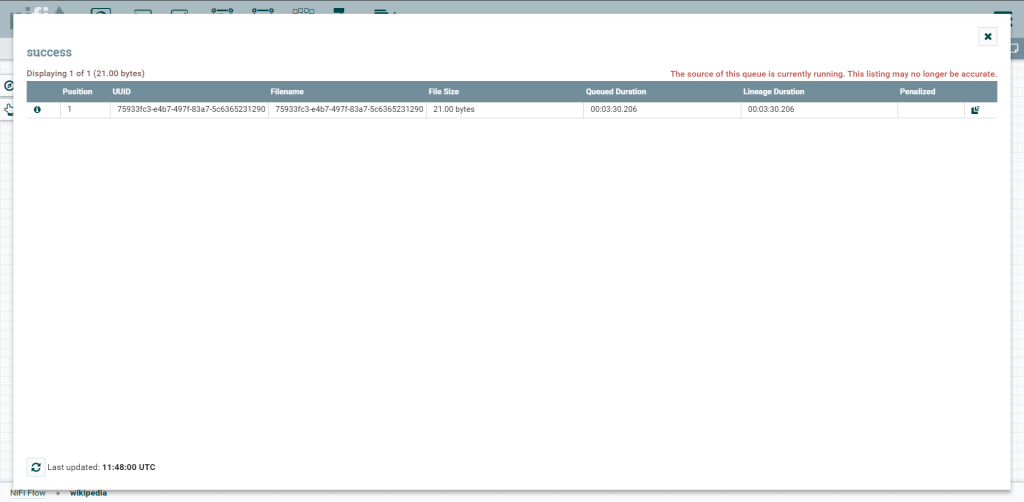
Clicando com o botão direito em cima do conector temos diversas opções. Podemos, inclusive inspecionar a fila de itens por processar consultando seus detalhes.
Concluindo
NiFi é uma ferramenta extremamente poderosa que permite que desenvolvamos lógicas complexas de integração, baseadas em padrões consagrados, sem que tenhamos que escrever uma linha de código. Além disso, NiFi permite que acompanhemos e controlemos a execução facilmente em uma interface fácil de entender.
Podemos ajudar você a adotar soluções como o NiFi em sua organização. Também adoraríamos entender o que tem feito para integrar suas aplicações.






