
Most of my client’s applications code is for parsing, caching, storing, aggregating, protecting and sharing data! It is not the kind of code that demands CPU power (except for the garbage collector).
Martin Kleppmann, in his excellent “Designing Data-Intensive Applications” book, describes this kind of applications as “Data-Intensive Applications.”
What are Data-Intensive Applications?
Following Kleppmann’s definition, Data-intensive applications are these where the more significant problems are:
- the amount of data,
- the complexity of data,
- the speed at which data is changing.
Exact what I have seen in the field.
Data-Intensive Applications building blocks
The standard building for data-intensive applications are:
- databases – to store data so that they, or another application, can find it again later;
- caches – to speed up reads remembering the result of expensive operations;
- message brokers – for message exchanging between processes and/or stream processing;
- batch processors – crunch big amounts of data
Besides of that, there are a lot of application code to orchestrate all this work.
Data-Intensive Applications Architecture
Considering archictecture as:
The structure of components, ther inter-relationships, and the principles and guidelines governing their design and evolution over time. (ISO/IEC 42010:2011)
Considering what we have seen, we could represent Data-Intensive applications as follows:
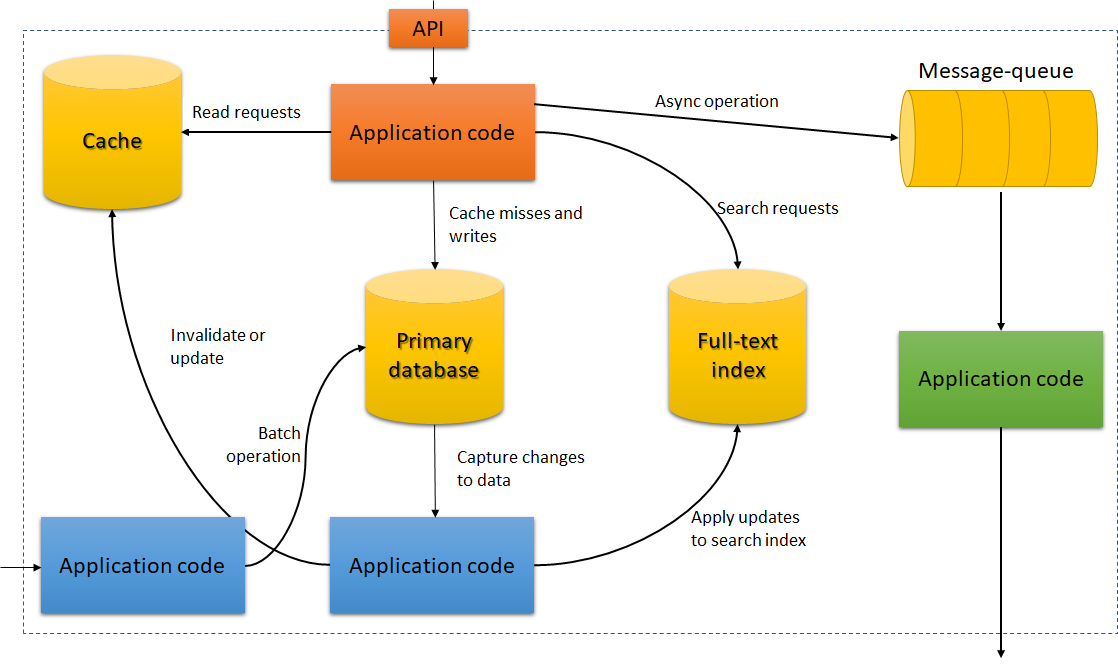
This diagram (adapted from the book), provides us with an excellent blueprint for a generic “Data-Intensive Application” architecture. Also, indicates the components we have to write.
PAUSE: Why I love RavenDB?
RavenDB is a powerful NoSQL database that provides built-in support for MapReduce, Full-Text indexing and more. Because of that, when using RavenDB, the need for separeted caching and full-text indexes is reduced and I need to write less code.
COMING BACK: Why is this view important?
Most of the code that I have seen do not have a proper separation of concerns. For example, there are a lot of caching logic mixed with reading data, updates to the full-text search indexes combined with the write operations, and so on. Unfortunately, the result is code hard to read, understand and, consequently, costly to maintain.
Call for Action
What about your code? Is that “data-intensive”? What about the organization of the components? Would it be something like I shared here?
Share your thoughts in the comments.






